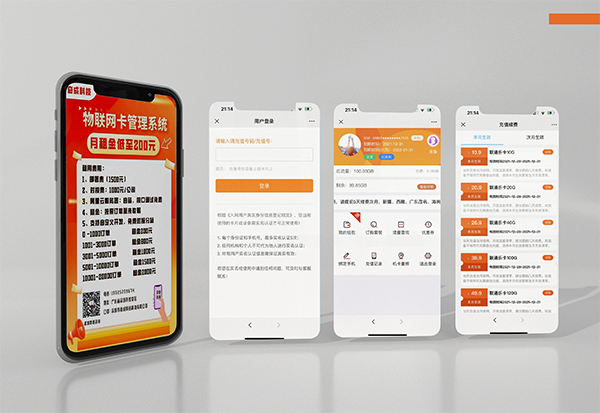
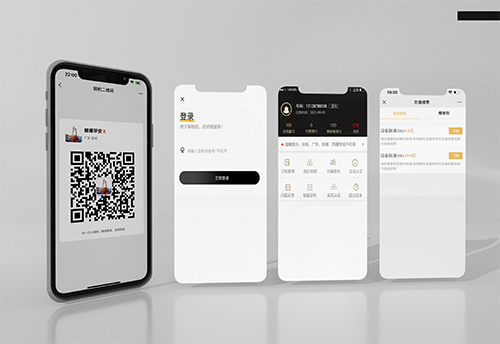
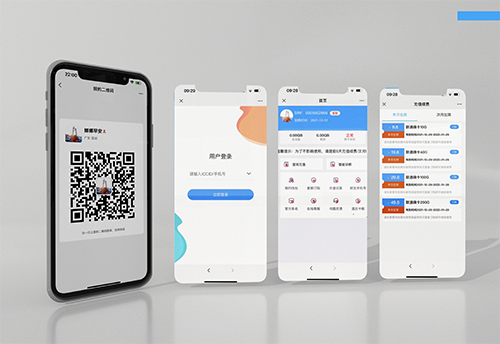
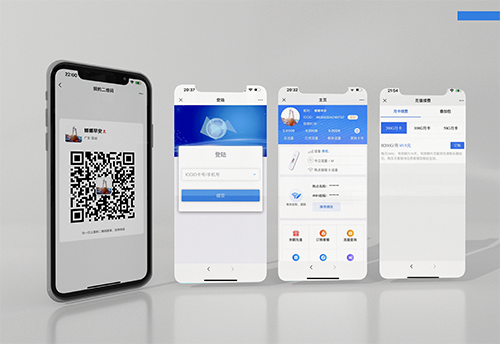
Focus on Internet technology services, development and applications, and provide a one-stop,
complete Internet of Things service management platform for enterprises and units.
灏景网络科技专注于物联网管理平台建设
因为专注,所以专业
迄今为止我们服务的客户超过
30000+,遍及各大行业
百分百的独特创意设计,纯定制
开发,让您的网站与众不同
良好的口碑是我们立足业界
的根本,客户满意度超99%

做SEO的同学都知道友情链接可以很好的引蜘蛛,但是偏偏有一些站长就是喜欢在友情链接上做手脚,这里列举常见的作弊手段,大家可以在交换友情链接的时候防范一下。作弊一:robots文件屏蔽链接对方网站robots屏蔽了所有的友情链接或者你的链接,那么这样百度是不会抓取你的网站的,这种交换没有意义,Disallow 意思就是不让抓取,看下对方robots文件是否有这样的写

企业需要做网站相信很多企业老板也都意识到了,但是还是有一些老板并怎么了解如何运用网站实现网络营销直接给公司带来利润。只是看到别的企业有网站,也就随大流随便的做了个网站,还有一个传统企业的老板根本就没有做网站的意识,任务纯粹是在浪费钱。鉴于还有很多客户朋友的这种误区,在此我们向客户朋友简单的介绍下传统企业为什么需要做网站。网站建设

很多企业网站做了官方网站,但是在经过一段时间以后,却发现自己文章也做了,外链也发了,但是网站排名还是没啥变化,这是咋回事呢,我们来分析一下大多企业网站的问题出在哪。第一点问题:对seo的策略问题网站建设初期可能直接外包了一家网站制作机构,这时候肯定非专业人士并没有关于SEO的概念,这就造成了前期网站没有针对SEO做布局,这时候招聘了一个SEO专员,但是